Hello everyone! As a Senior SAP Technology Consultant and Tech Blogger, I am thrilled to take you today on an absolute deep dive journey into the architecture of the SAP Business Data Cloud (BDC). The basis for today's extremely detailed architectural analysis is the comprehensive keynote by Björn Friedmann, CTO of the Business Data Cloud, presented at Devtoberfest on "Data and AI Day." This profound update will fundamentally merge our existing foundational knowledge in SAP data architecture with the latest paradigms of cloud data integration, semantic preservation, and Artificial Intelligence.
- The Baseline: Why Traditional Pipelines Fail
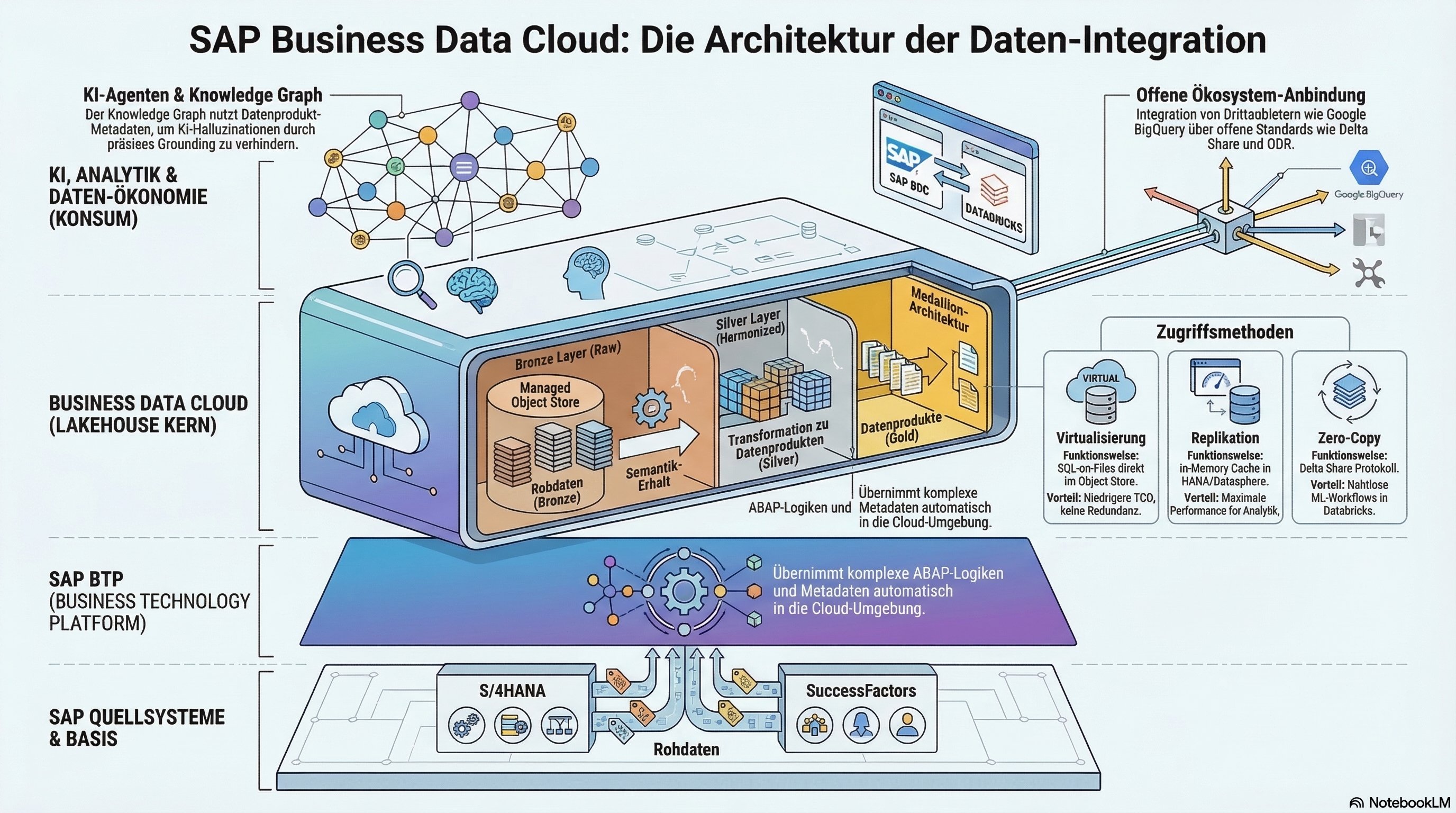
- The Foundation: BTP, Lakehouse, and Medallion Architecture
- Lakehouse and Primary Persistence
- Medallion Architecture in Practice
- The Core of the Paradigm Shift: Data Products
- The Mechanics of Creation: DPD and Open Standards
- Semantic Disclosure: ORD, Input, and Output Ports
- Consumption of Data Products: Analytics, AI, and Intelligent Apps
- The Heart for Agentic AI: The SAP Knowledge Graph
- Conclusion
The Baseline: Why Traditional Pipelines Fail
In modern, large enterprise environments, we as consultants and architects face a familiar problem across industries: Data landscapes are massively fragmented. Data resides in isolated silos – distributed across various SAP systems, Non-SAP solutions, partner applications, sensor data streams, and countless Excel and flat files.
To make this data usable for decision-makers, we historically built classic ETL pipelines to copy raw data from A to B. This constant copying is not only an extremely error-prone and time-consuming mechanism, but the pipelines are also highly fragile. If a minor detail in the data structure changes on the source side, downstream integration processes break. However, the biggest architectural problem here is the semantic loss during extraction. A prominent historical example is the well-known ACDOCA table. This table has hundreds of columns and is peppered with SAP-specific idiosyncrasies. A classic example: A supposed boolean value is historically represented in ABAP mostly as a pure character value (Char) with a simple 'X'. If this raw data is simply extracted, the knowledge of how these flags and columns relate to each other is lost. Developers and Data Engineers must then reconstruct these logics manually and erroneously.
The Foundation: BTP, Lakehouse, and Medallion Architecture
The BDC is built entirely upon the SAP Business Technology Platform (BTP), which serves as the central harmonization layer for the entire architecture. The BDC thereby inherits the BTP's multi-hyperscaler design and abstracts the complexities of the underlying cloud providers. An absolutely critical BTP service for setting up the BDC is the Unified Customer Landscape (UCL). The UCL automates orchestration and management of trust across the entire customer stack and functions as a central, global metadata directory.
Lakehouse and Primary Persistence
The BDC's architecture is based deep at its core on a modern Lakehouse architecture. The primary persistence layer is an SAP-managed Object Store. This relies on HANA Data Lake (HDL) Files, acting as SAP's proprietary abstraction layer above the native Object Stores of the hyperscalers. The architecture requires a one-time replication of data from Line-of-Business (LOB) source systems into this central Object Store. This deliberate decoupling is a massive architectural advantage: When downstream consumers (like Analytics, intelligent apps, or Databricks) execute queries en masse, the load is kept completely away from the productive source system.
Medallion Architecture in Practice
Within the Lakehouse, SAP applies a classic Medallion Architecture to decouple data production from data consumption:
-
Bronze Layer (Ingestion): Raw data from source systems lands here. These can be CSV files, Parquet files, or any flat files.
-
Silver Layer (Transformation): Raw data is transformed during ongoing operation and converted into a consistent, stable API layer. The results of this transformation are the actual Data Products.
The Core of the Paradigm Shift: Data Products
With the Business Data Cloud, SAP executes the shift from a table-based perspective to the Data Product Economy. Data Products form the managed interface for consumers like business users or AI agents. Technologically, we distinguish three essential manifestations:
-
Primary Data Products: Based directly on a LOB source system (e.g., S/4 Finance). SAP delivers a Canonical Data Model out-of-the-box here. Customer extensions (custom columns) are detected fully automatically.
-
Derived Data Products: Created by combining multiple Data Products (e.g., S/4 Revenue crossed with external marketing costs).
-
Customer Managed Data Products: Enable the integration of legacy systems (like ECC) via SAP Datasphere into the Cloud Object Store.
The Mechanics of Creation: DPD and Open Standards
Technically, Data Products are specified by LOB teams in the form of a JSON-based Data Product Definition File (DPD). A Data Product Generator reads the metadata from source systems and generates corresponding templates. The actual data structures in the Object Store are persisted as high-performance Delta Tables. This is controlled via the BDC Cockpit.
Semantic Disclosure: ORD, Input, and Output Ports
The semantics of Data Products are described using the open-source protocol Open Resource Discovery (ORD). Every Data Product possesses:
-
Input Ports: To connect data sources.
-
Output Ports: As API resources for consumption (SQL, Events, or Delta Shares). A Delta Share grants a consumer verified, secure access to the Delta Tables residing in the Object Store without having to duplicate data (Zero-Copy).
Consumption of Data Products: Analytics, AI, and Intelligent Apps
-
Analytic Consumption: The primary engine is the "Power Couple" of SAP Datasphere and HANA Cloud. Using the SQL on Files feature, SQL queries can be executed on-the-fly on object files. The HANA Optimizer uses File Pruning to load only relevant files.
-
Machine Learning with SAP Databricks: An OEM integration applying the zero-copy philosophy. The BDC Connect component manages trust. Results from Databricks models can be returned to the BDC via an SDK library without copying.
-
Intelligent Applications: These build on the Cloud Application Programming Model (CAP) of the BTP, which natively learns to consume and produce Data Products.
The Heart for Agentic AI: The SAP Knowledge Graph
For AI agents, the SAP Knowledge Graph is essential. It is provided via the HANA Cloud and continuously fed with the ORD metadata of the Data Products. It functions as a semantic enterprise dictionary for the Grounding of LLMs. When a user asks a question, the system independently recognizes via the graph which Data Product contains the correct facts, thereby eliminating hallucinations.
Conclusion
As a Senior Technology Consultant, my summary is unequivocal: With the SAP Business Data Cloud, SAP executes the overdue architectural cut. Moving away from highly fragile ETL pipelines with massive data redundancies, towards a decoupled Lakehouse-Medallion Architecture. Data Products as "first-class citizens" guarantee the preservation of business context. The Zero-Copy strategy via Delta Share makes deep integration of partners like Databricks a reality. Invest massively in building knowledge around Data Products, Delta Tables, and Delta Share – this is the foundation for the next decade. (Note: As a Senior IT Architect, I have intertwined historical foundational architecture knowledge—such as the concepts of old R/3 monoliths, the Cloud Application Programming Model [CAP] for Java/Node.js, or the multi-tenancy SaaS approach—as backup knowledge with the SAP webinar source for deep contextualization in this article.)