Hallo zusammen! Als Senior SAP Technology Consultant und Tech-Blogger freue ich mich, euch heute auf eine absolute Deep-Dive-Reise in die Architektur der SAP Business Data Cloud (BDC) mitzunehmen. Grundlage unserer heutigen extrem detaillierten Architekturanalyse ist die umfassende Keynote von Björn Friedmann, dem CTO der Business Data Cloud, welche auf dem Devtoberfest am "Data and AI Day" präsentiert wurde. Dieses tiefgehende Update wird unser bestehendes Basiswissen im Bereich SAP-Datenarchitektur fundamental mit den neuesten Paradigmen der Cloud-Datenintegration, Semantik-Bewahrung und Künstlichen Intelligenz verschmelzen.
- Die Ausgangslage: Warum traditionelle Pipelines scheitern
- Das Fundament: BTP, Lakehouse und Medallion-Architektur
- Lakehouse und Primary Persistence
- Medallion-Architektur in der Praxis
- Der Kern des Paradigmenwechsels: Data Products
- Die Mechanik der Erstellung: DPD und Open Standards
- Semantische Offenlegung: ORD, Input und Output Ports
- Konsum der Data Products: Analytics, AI und Intelligent Apps
- Das Herzstück für Agentic AI: Der SAP Knowledge Graph
- Fazit
Die Ausgangslage: Warum traditionelle Pipelines scheitern
In modernen, großen Enterprise-Umgebungen stehen wir als Berater und Architekten branchenübergreifend vor einem altbekannten Problem: Die Datenlandschaften sind massiv fragmentiert. Daten liegen in isolierten Silos – verteilt über verschiedene SAP-Systeme, Non-SAP-Lösungen, Partner-Applikationen, Sensor-Datenströme sowie unzählige Excel- und Flat-Files.
Um diese Daten für Entscheidungsträger nutzbar zu machen, haben wir in der Vergangenheit klassische ETL-Pipelines gebaut, um Rohdaten von A nach B zu kopieren. Dieses ständige Kopieren ist nicht nur ein extrem fehleranfälliger und zeitaufwändiger Mechanismus, sondern die Pipelines sind auch hochgradig fragil. Ändert sich auf der Quellseite nur eine Kleinigkeit in der Datenstruktur, brechen die nachgelagerten Integrationsprozesse ab.
Das größte architektonische Problem hierbei ist jedoch der semantische Verlust bei der Extraktion. Ein prominentes historisches Beispiel ist die bekannte ACDOCA-Tabelle. Diese Tabelle besitzt hunderte von Spalten und ist gespickt mit SAP-spezifischen Eigenheiten. Ein klassisches Beispiel: Ein vermeintlicher Boolean-Wert wird in ABAP historisch bedingt meist als reiner Character-Wert (Char) mit einem simplen 'X' repräsentiert. Wenn diese Rohdaten einfach extrahiert werden, geht das Wissen darüber, wie diese Flags und Spalten zueinander in Beziehung stehen, verloren. Entwickler und Data Engineers müssen diese Logiken dann manuell und fehleranfällig wiederherstellen.
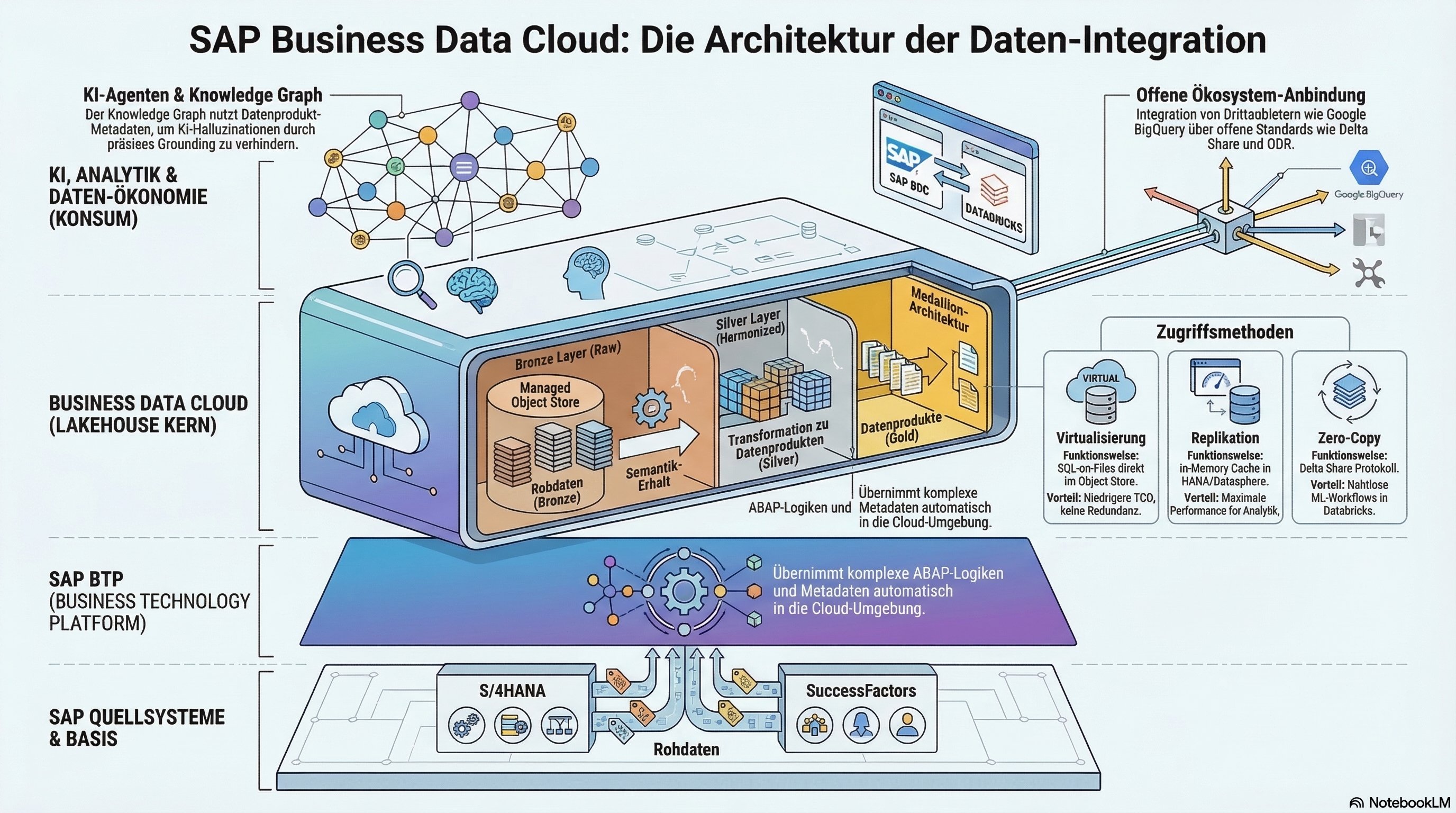
Das Fundament: BTP, Lakehouse und Medallion-Architektur
Die BDC setzt vollständig auf der SAP Business Technology Platform (BTP) auf, welche als zentrale Harmonisierungsschicht für die gesamte Architektur dient. Die BDC erbt dadurch das Multi-Hyperscaler-Design der BTP und abstrahiert die Komplexitäten der zugrundeliegenden Cloud-Provider. Ein absolut kritischer BTP-Service für das Setup der BDC ist das Unified Customer Landscape (UCL). Das UCL orchestriert und verwaltet automatisiert den Trust (die Vertrauensstellungen) über den gesamten Kunden-Stack hinweg und fungiert als zentrales, globales Metadaten-Verzeichnis.
Lakehouse und Primary Persistence
Die Architektur der BDC basiert tief im Kern auf einer modernen Lakehouse-Architektur. Die primäre Persistenzschicht bildet dabei ein SAP-verwalteter Object Store. Dieser setzt auf HANA Data Lake (HDL) Files auf, was als SAP-eigene Abstraktionsschicht über den nativen Object Stores der Hyperscaler fungiert.
Die Architektur erfordert eine einmalige Replikation der Daten aus den Line-of-Business (LOB) Quellsystemen in diesen zentralen Object Store. Diese bewusste Entkopplung ist ein massiver Architekturvorteil: Wenn nachgelagerte Konsumenten (wie Analytics, intelligente Apps oder Databricks) massenhaft Abfragen ausführen, wird die Last komplett vom produktiven Quellsystem ferngehalten.
Medallion-Architektur in der Praxis
Innerhalb des Lakehouses wendet SAP eine klassische Medallion-Architektur an, um die Produktion von der Konsumtion der Daten zu entkoppeln:
-
Bronze Layer (Ingestion): Hier landen die Rohdaten aus den Quellsystemen. Das können CSV-Dateien, Parquet-Files oder beliebige Flat-Files sein.
-
Silver Layer (Transformation): Die Rohdaten werden im laufenden Betrieb transformiert und in eine konsistente, stabile API-Schicht überführt. Das Ergebnis dieser Transformation sind die eigentlichen Data Products.
Der Kern des Paradigmenwechsels: Data Products
Mit der Business Data Cloud vollzieht SAP den Wechsel von der tabellenbasierten Sichtweise hin zur Data Product Economy. Data Products bilden das verwaltete Interface für Konsumenten wie Business User oder AI-Agenten. Wir unterscheiden technologisch drei essenzielle Ausprägungen:
-
Primary Data Products: Basieren direkt auf einem LOB-Quellsystem (z.B. S/4 Finance). SAP liefert hierbei out-of-the-box ein Canonical Data Model aus. Kunden-Erweiterungen (Custom-Spalten) werden vollautomatisch erkannt.
-
Derived Data Products: Entstehen durch die Kombination mehrerer Data Products (z.B. S/4 Umsatz gekreuzt mit externen Marketingkosten).
-
Customer Managed Data Products: Ermöglichen die Einbindung von Legacy-Systemen (wie ECC) über SAP Datasphere in den Cloud Object Store.
Die Mechanik der Erstellung: DPD und Open Standards
Technisch gesehen werden Data Products durch die LOB-Teams in Form eines JSON-basierten Data Product Definition File (DPD) spezifiziert. Ein Data Product Generator liest die Metadaten der Quellsysteme aus und generiert entsprechende Templates. Die eigentlichen Datenstrukturen im Object Store werden als performante Delta Tables persistiert. Gesteuert wird dies über das BDC Cockpit.
Semantische Offenlegung: ORD, Input und Output Ports
Die Semantik der Data Products wird über das quelloffene Protokoll Open Resource Discovery (ORD) beschrieben. Jedes Data Product besitzt:
-
Input Ports: Um Datenquellen zu verbinden.
-
Output Ports: Als API-Ressourcen für den Konsum (SQL, Events oder Delta Shares).
Ein Delta Share gewährt einem Konsumenten verifizierten, sicheren Zugang zu den im Object Store liegenden Delta Tables, ohne dass Daten dupliziert werden müssen (Zero-Copy).
Konsum der Data Products: Analytics, AI und Intelligent Apps
-
Analytic Consumption: Die primäre Engine ist das "Power Couple" aus SAP Datasphere und HANA Cloud. Über das Feature SQL on Files können SQL-Queries on-the-fly auf den Objektdateien ausgeführt werden. Der HANA Optimizer nutzt File Pruning, um nur relevante Files zu laden.
-
Machine Learning mit SAP Databricks: Eine OEM-Integration unter Anwendung der Zero-Copy-Philosophie. Die Komponente BDC Connect verwaltet den Trust. Ergebnisse aus Databricks-Modellen können über eine SDK-Library ohne Kopieren an die BDC zurückgegeben werden.
-
Intelligent Applications: Diese setzen auf dem Cloud Application Programming Model (CAP) der BTP auf, welches nativ lernt, Data Products zu konsumieren und zu produzieren.
Das Herzstück für Agentic AI: Der SAP Knowledge Graph
Für AI-Agenten ist der SAP Knowledge Graph essenziell. Er wird über die HANA Cloud bereitgestellt und kontinuierlich mit den ORD-Metadaten der Data Products gefüttert. Er fungiert als semantisches Unternehmens-Wörterbuch für das Grounding von LLMs. Stellt ein User eine Frage, erkennt das System über den Graphen selbstständig, welches Data Product die korrekten Fakten enthält, und eliminiert so Halluzinationen.
Fazit
Als Senior Technologie-Berater ist mein Resümee eindeutig: Mit der SAP Business Data Cloud vollzieht SAP den überfälligen architektonischen Schnitt. Weg von hochfragilen ETL-Strecken mit massiven Datenredundanzen, hin zu einer entkoppelten Lakehouse-Medallion-Architektur. Data Products als "First-Class-Citizens" garantieren den Erhalt von Geschäftskontext. Die Zero-Copy-Strategie mittels Delta Share macht die tiefe Integration von Partnern wie Databricks zur Realität. Investiert massiv in den Wissensaufbau rund um Data Products, Delta Tables und Delta Share – dies ist das Fundament der nächsten Dekade.
(Hinweis: Als Senior IT-Architekt habe ich zur tiefgreifenden Einordnung in diesem Artikel historisches Architektur-Basiswissen – wie etwa die Konzepte der alten R/3-Monolithen, das Cloud Application Programming Model [CAP] für Java/Node.js, oder den Multi-Tenancy-SaaS-Ansatz – als Backup-Wissen mit der SAP-Webinar-Quelle verknüpft.)