Welcome back to the architectural drawing board! On March 8, 2023, SAP made an announcement that massively shook the foundations of enterprise data architecture: SAP Data Warehouse Cloud (DWC) is history. Its successor is called SAP Datasphere. Anyone who thinks this is merely a clever marketing rebranding is profoundly mistaken. It is the starting gun for an entirely new data strategy: The Business Data Fabric.
As a Senior SAP Consultant, today I analyze the technical paradigm shifts, the new modeling approaches, and above all, the radical opening of the SAP ecosystem (Databricks, Confluent, Collibra) that accompanies this release.
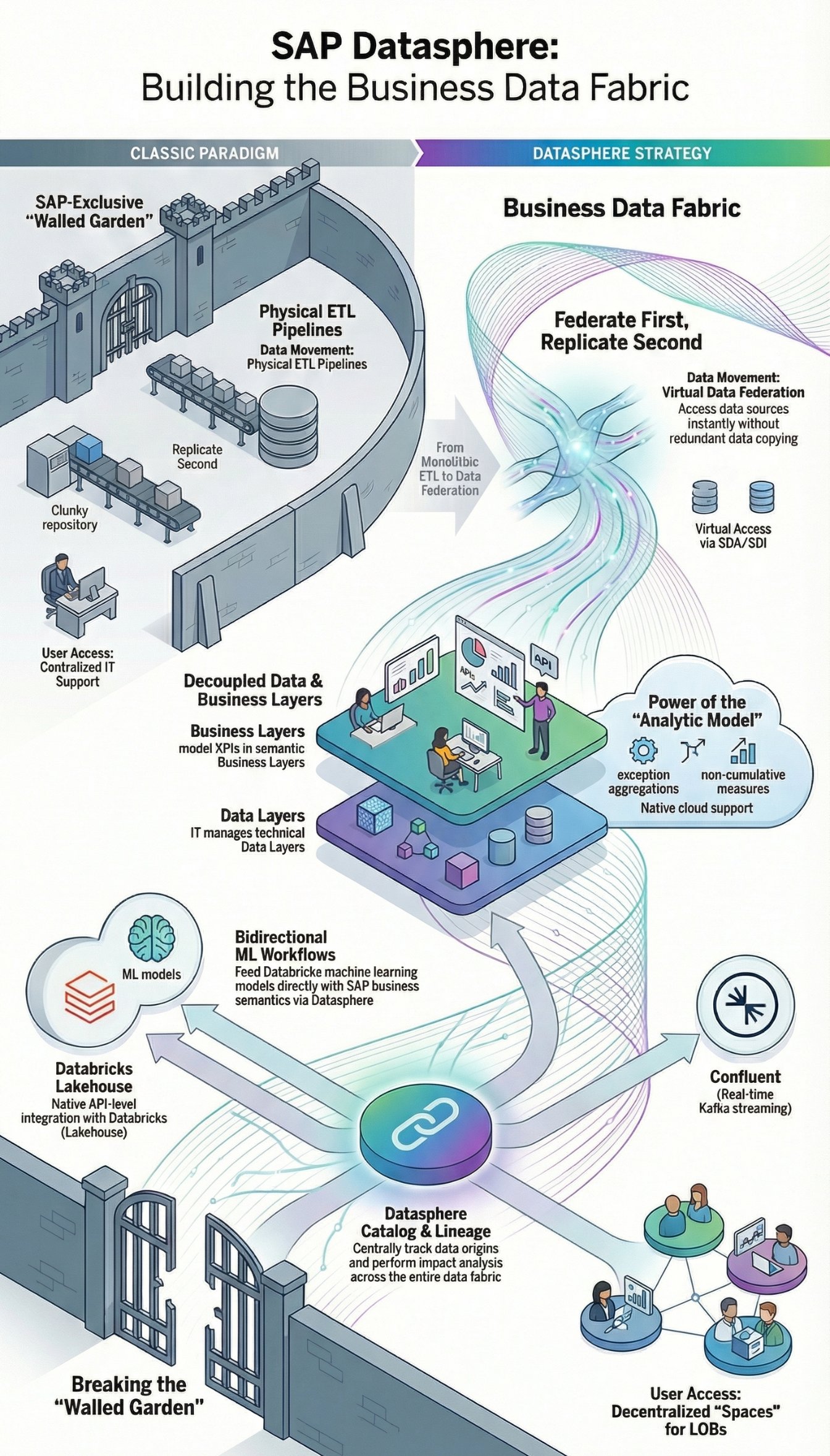
The Death of Monstrous ETL Pipelines
For decades, SAP data warehouses (from classic SAP BW 3.5 to BW 7.5 and BW/4HANA) were based on a strict dogma: data copying. Terabytes of data were physically pumped from source systems into the data warehouse via complex and error-prone ETL (Extract, Transform, Load) pipelines. The result? Redundant data, high latencies, and massive storage costs.
The architecture of SAP Datasphere now forces the ultimate breakthrough of Data Federation. Instead of copying data, it remains in its source systems (whether in S/4HANA, Google BigQuery, Snowflake, or Amazon S3). Datasphere accesses it virtually via Smart Data Access (SDA) and Smart Data Integration (SDI). Only when performance reasons (e.g., complex historical aggregations) strictly require it, data is persisted via the integrated Data Flow (Replication). The principle is: Federate first, replicate second.
Core Concepts: Spaces, Data Layer, and Business Layer
Datasphere retains the brilliant separation mechanisms of DWC and expands them massively. The architecture consistently separates physical data management and business semantics:
-
Space Management: Spaces are virtual, isolated workspaces for different departments (LOBs - Lines of Business). An "HR Space" and a "Finance Space" can manage their own compute and storage resources. They can share data with each other (Space Sharing) without the IT Basis team having to manually bend authorizations at the database level.
-
Data Layer (IT Focus): This is where Data Engineers work. They connect external sources, define virtual tables, cleanse data using SQLScript or graphical views, and provide clean, normalized data models.
-
Business Layer (Business Focus): This is where the magic happens. Controllers or HR analysts model their KPIs graphically, without SQL knowledge. They use the clean views from the Data Layer and enrich them with business logic (e.g., "Revenue = Quantity * Price").
The New Modeling Paradigm: Analytic Model
With the launch of SAP Datasphere in spring 2023, the old Analytical Dataset from the DWC era effectively becomes obsolete. The new centerpiece of modeling is the Analytic Model.
This new artifact finally brings the highly complex OLAP capabilities, which BW/4HANA developers often missed in DWC, natively into the cloud. The Analytic Model supports complex exception aggregations, non-cumulative measures, restricted measures, and time-dependent master data directly in the modeling interface before the data is passed on to the SAP Analytics Cloud (SAC). The beauty of it: The generation of the associated Calculation View at the underlying HANA Cloud level happens completely transparently in the background.
The Open Data Ecosystem: The End of the "Walled Garden"
Arguably the most radical architectural update of Datasphere is its technological opening. SAP has recognized that modern companies operate hybrid multi-cloud landscapes. Instead of forcing customers into an SAP-exclusive "walled garden," Datasphere integrates external hyperscaler services natively at the API level:
-
Databricks: Deep integration makes it possible to marry the Databricks Data Lakehouse approach directly with SAP data. Machine Learning (ML) models trained in Apache Spark on Databricks can be bidirectionally fed with SAP business semantics (from Datasphere).
-
Confluent: For event streaming. Instead of static batch loads, Datasphere can consume real-time data streams (Data in Motion) directly via Apache Kafka topics from Confluent and turn them into real-time dashboards.
-
Collibra & DataRobot: Integration for enterprise-wide Data Governance (Collibra) and automated AutoML workflows (DataRobot) without losing the context of the SAP data.
Datasphere Catalog and the Path Forward
Another massive feature of the 2023 release is the integrated Datasphere Catalog. It acts as a central Data Dictionary and Lineage tool. Administrators and business users can track exactly where a data point originates (Data Lineage) and what impact a change to a source table will have on downstream dashboards (Impact Analysis).
Conclusion for Enterprise Architects
SAP Datasphere is the final puzzle piece in SAP's cloud data strategy. For IT architects, 2023 marks the definitive end of monolithic BW systems. The Business Data Fabric shifts our tasks: We no longer need to calculate hard drive capacities for ETL copies. Our new core task is orchestrating virtual data streams (Data Federation) and securing semantic context across system boundaries.
Anyone still building new, massive ETL pipelines into a standalone BW today is ignoring the architectural shift. The future belongs to decentralized "Spaces," virtual views, and an ecosystem that accepts Databricks and Kafka as equal partners alongside the ABAP core.