Willkommen zurück am Architektur-Reißbrett! Am 8. März 2023 hat SAP eine Ankündigung gemacht, die die Fundamente der Enterprise-Datenarchitektur massiv erschüttert: Die SAP Data Warehouse Cloud (DWC) ist Geschichte. Ihr Nachfolger heißt SAP Datasphere. Wer nun denkt, es handele sich hierbei lediglich um ein geschicktes Marketing-Rebranding, irrt gewaltig. Es ist der Startschuss für eine völlig neue Datenstrategie: Die Business Data Fabric.
Als Senior SAP Consultant analysiere ich heute die technischen Paradigmenwechsel, die neuen Modellierungsansätze und vor allem die radikale Öffnung des SAP-Ökosystems (Databricks, Confluent, Collibra), die mit diesem Release einhergeht.
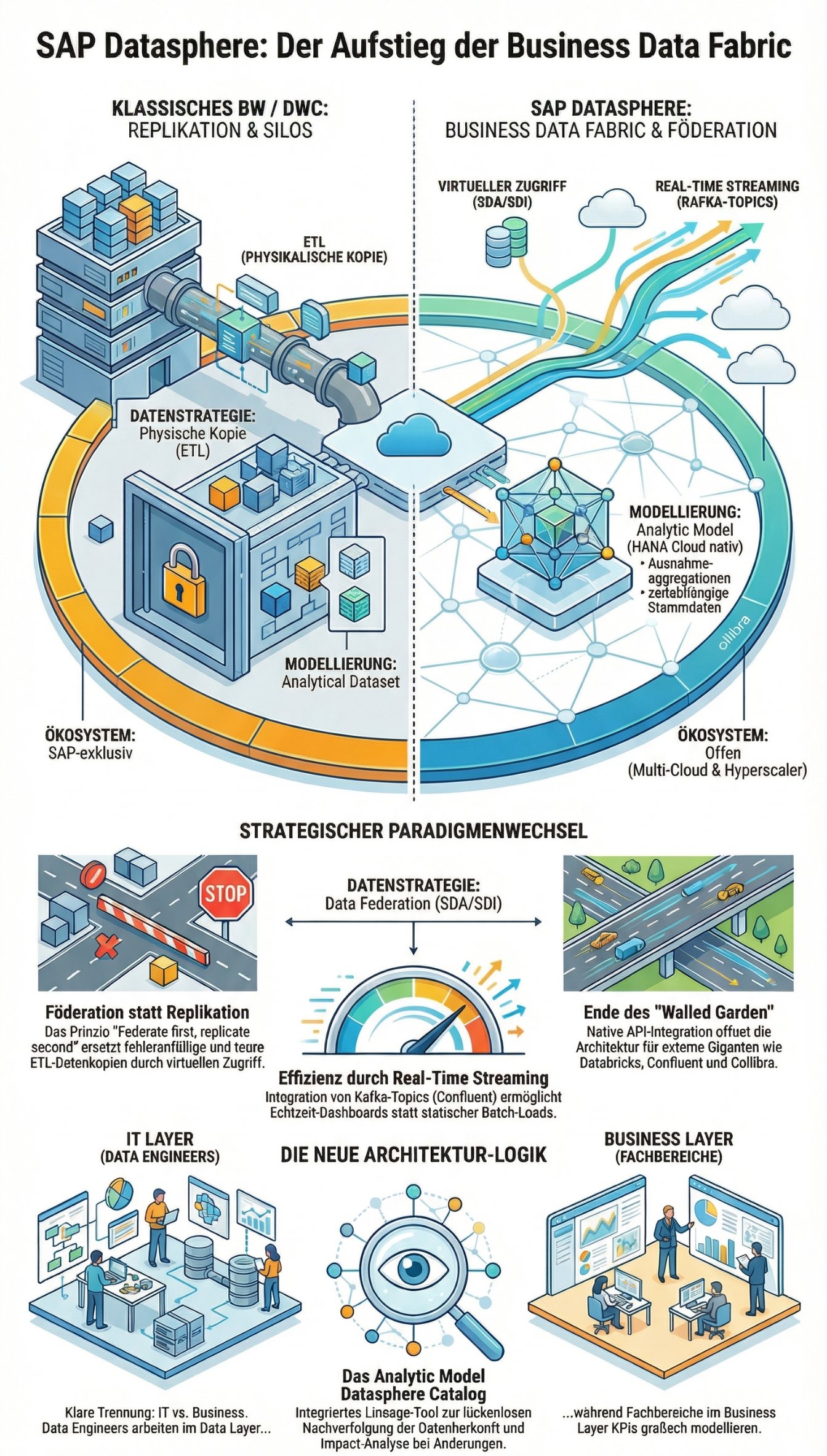
Der Tod der monströsen ETL-Pipelines
Jahrzehntelang basierten SAP-Data-Warehouses (vom klassischen SAP BW 3.5 über BW 7.5 bis hin zum BW/4HANA) auf einem strikten Dogma: Datenkopie. Terabytes an Daten wurden via komplexer und fehleranfälliger ETL-Strecken (Extract, Transform, Load) physisch aus Quellsystemen in das Data Warehouse gepumpt. Das Ergebnis? Redundante Daten, hohe Latenzen und massive Storage-Kosten.
Die Architektur von SAP Datasphere erzwingt nun den endgültigen Durchbruch der Data Federation. Anstatt Daten zu kopieren, verbleiben sie in ihren Quellsystemen (ob in S/4HANA, Google BigQuery, Snowflake oder Amazon S3). Datasphere greift über Smart Data Access (SDA) und Smart Data Integration (SDI) virtuell darauf zu. Nur wenn Performance-Gründe (z. B. komplexe historische Aggregationen) es zwingend erfordern, werden Daten über den integrierten Data Flow persistiert (Replication). Das Prinzip lautet: Federate first, replicate second.
Kernkonzepte: Spaces, Data Layer und Business Layer
Datasphere behält die brillanten Trennungsmechanismen des DWC bei und erweitert sie massiv. Die Architektur trennt physische Datenverwaltung und geschäftliche Semantik konsequent:
-
Space Management: Spaces sind virtuelle, isolierte Arbeitsbereiche für verschiedene Fachbereiche (LOBs - Lines of Business). Ein "HR-Space" und ein "Finance-Space" können ihre eigenen Compute- und Storage-Ressourcen verwalten. Sie können Daten miteinander teilen (Space Sharing), ohne dass die IT-Basis manuell Berechtigungen auf Datenbankebene umbiegen muss.
-
Data Layer (IT-Fokus): Hier arbeiten die Data Engineers. Sie binden externe Quellen an, definieren die Virtual Tables, bereinigen die Daten mittels SQLScript oder grafischen Views und stellen saubere, normalisierte Datenmodelle bereit.
-
Business Layer (Fachbereich-Fokus): Hier passiert die Magie. Controller oder HR-Analysten modellieren ihre KPIs grafisch, ohne SQL-Kenntnisse. Sie nutzen die sauberen Views aus dem Data Layer und reichern sie mit Geschäftslogik (z. B. "Umsatz = Menge * Preis") an.
Das neue Modellierungs-Paradigma: Analytic Model
Mit dem Launch von SAP Datasphere im Frühjahr 2023 wird das alte Analytical Dataset aus der DWC-Ära de facto obsolet. Das neue Herzstück der Modellierung ist das Analytic Model.
Dieses neue Artefakt bringt endlich die hochkomplexen OLAP-Fähigkeiten, die BW/4HANA-Entwickler bei der DWC oft vermisst haben, nativ in die Cloud. Das Analytic Model unterstützt komplexe Exception Aggregations (Ausnahmeaggregationen), Non-Cumulative Measures, restricted Measures und zeitabhängige Stammdaten direkt in der Modellierungsoberfläche, bevor die Daten an die SAP Analytics Cloud (SAC) durchgereicht werden. Das Schöne daran: Die Generierung des zugehörigen Calculation Views auf der unterliegenden HANA Cloud-Ebene passiert völlig transparent im Hintergrund.
Das Open Data Ecosystem: Das Ende des "Walled Garden"
Das wohl radikalste Architektur-Update von Datasphere ist die technologische Öffnung. SAP hat erkannt, dass moderne Unternehmen hybride Multi-Cloud-Landschaften betreiben. Anstatt Kunden in einen SAP-exklusiven "Walled Garden" zu zwingen, integriert Datasphere externe Hyperscaler-Dienste nativ auf API-Ebene:
-
Databricks: Die tiefe Integration ermöglicht es, den Databricks Data Lakehouse-Ansatz direkt mit SAP-Daten zu verheiraten. Machine Learning (ML) Modelle, die in Apache Spark auf Databricks trainiert wurden, können bidirektional mit SAP-Business-Semantik (aus Datasphere) gefüttert werden.
-
Confluent: Für Event-Streaming. Anstatt statischer Batch-Loads kann Datasphere Echtzeit-Datenströme (Data in Motion) über Apache Kafka-Topics von Confluent direkt konsumieren und in Echtzeit-Dashboards verwandeln.
-
Collibra & DataRobot: Integration für unternehmensweite Data Governance (Collibra) und automatisierte AutoML-Workflows (DataRobot), ohne den Kontext der SAP-Daten zu verlieren.
Datasphere Catalog und der Weg in die Zukunft
Ein weiteres massives Feature des 2023er Releases ist der integrierte Datasphere Catalog. Er fungiert als zentrales Data Dictionary und Lineage-Tool. Administratoren und Business User können exakt nachvollziehen, woher ein Datenpunkt stammt (Data Lineage) und welche Auswirkungen eine Änderung an einer Quelltabelle auf nachgelagerte Dashboards hat (Impact Analysis).
Fazit für Enterprise Architekten
SAP Datasphere ist das letzte Puzzleteil in SAPs Cloud-Datenstrategie. Für IT-Architekten bedeutet das Jahr 2023 das endgültige Ende der monolithischen BW-Systeme. Die Business Data Fabric verlagert unsere Aufgaben: Wir müssen keine Festplatten-Kapazitäten für ETL-Kopien mehr berechnen. Unsere neue Kernaufgabe ist das Orchestrieren von virtuellen Datenströmen (Data Federation) und das Sichern des semantischen Kontexts über Systemgrenzen hinweg.
Wer heute noch neue, massive ETL-Strecken in ein Standalone-BW baut, ignoriert den architektonischen Shift. Die Zukunft gehört dezentralen "Spaces", virtuellen Views und einem Ökosystem, das Databricks und Kafka als gleichwertige Partner neben dem ABAP-Kern akzeptiert.