Welcome back to the architecture blog. This spring, we are celebrating a massive anniversary in enterprise IT: 10 years of SAP HANA. What began in 2010 as a blazingly fast but extremely rigid on-premise appliance has now reached its preliminary evolutionary peak. With the official launch of SAP HANA Cloud, SAP is making the radical cut from an appliance to a true, native Database-as-a-Service (DBaaS).
This article is not a marketing recap, but a deep dive into the altered system architecture, the storage hierarchies, and the new paradigms that we as Basis and Database Administrators must master from now on.
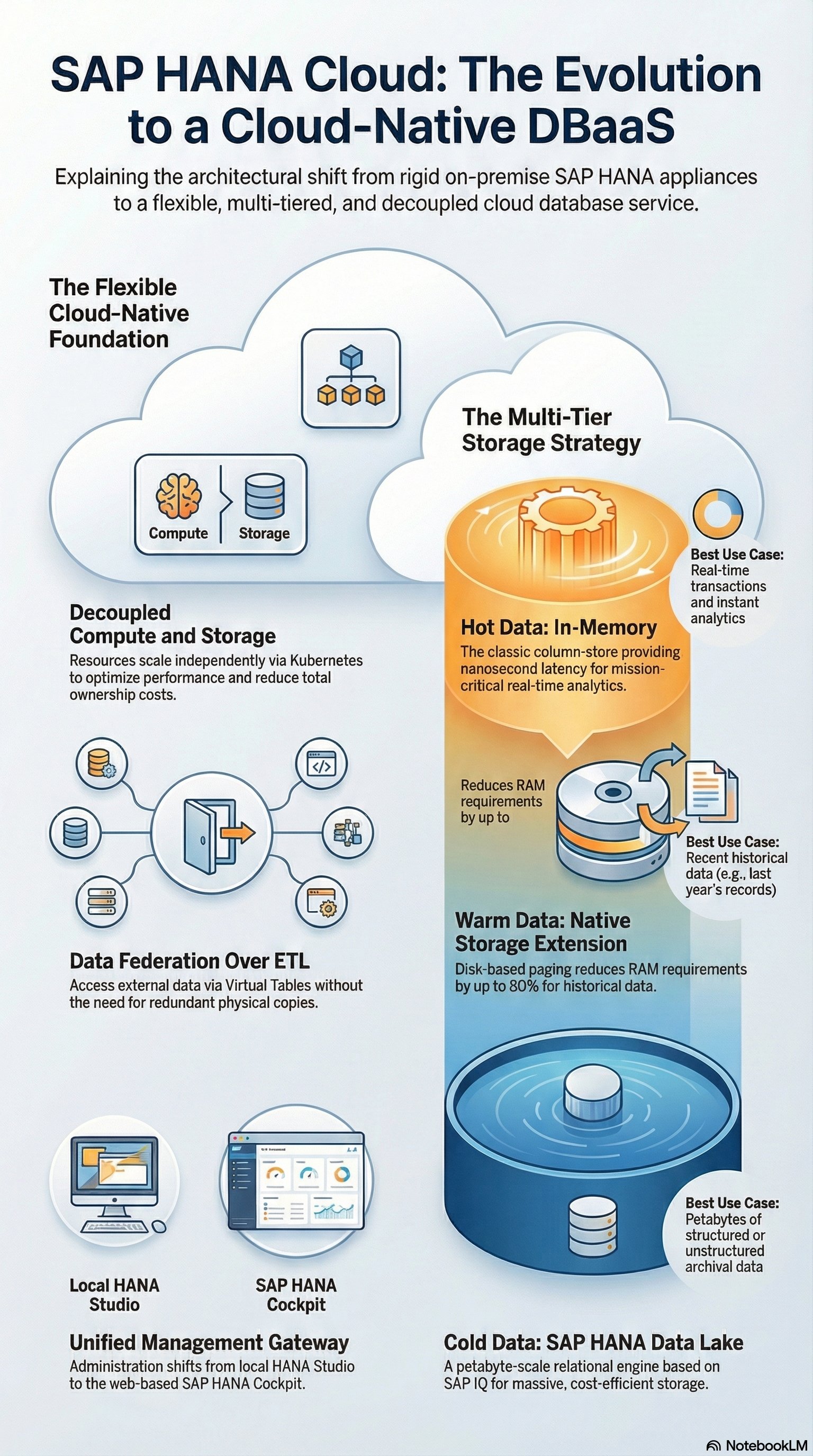
The Fundamental Shift: Decoupling Compute and Storage
The biggest architectural bottleneck of classic HANA on-premise installations was the tight coupling of CPU and RAM. A scale-up often meant expensive hardware upgrades where storage and computing power had to be scaled in a fixed ratio (e.g., in TDI sizing), even if only more storage space was needed.
SAP HANA Cloud completely breaks this construct based on modern container orchestration (underneath the hood, Kubernetes). Compute nodes and storage resources can now be scaled completely independently of each other. If a month-end closing requires massive CPU power, the compute tier scales up. If only archive storage is needed afterward, the storage tier scales while the CPUs are spun down. This is the key to a massive reduction in TCO (Total Cost of Ownership).
Multi-Tier Storage: From In-Memory to the Data Lake
The architecture of SAP HANA Cloud forces us to stop stubbornly keeping all data in RAM and instead design an intelligent Multi-Tier Storage Strategy:
-
In-Memory (Hot Data): The classic HANA Column-Store. Expensive, but with latencies in the nanosecond range for business-critical real-time analytics and transactions.
-
Native Storage Extension (NSE) (Warm Data): An integrated disk-based extension. Data that is used less frequently (e.g., historical FI documents from the previous year) is moved here. Through paging mechanisms, the RAM requirement is reduced by up to 80%, with only a moderate loss of performance.
-
SAP HANA Cloud, Data Lake (Cold Data): This is where the true architectural newcomer lies. The Data Lake Relational Engine is technologically based on the massively parallel SAP IQ database architecture. It is designed to store petabytes of unstructured and structured data extremely cost-effectively. The highlight: The Data Lake is seamlessly integrated into the HANA query engine. A SQL query can transparently join data from the in-memory storage with data from the Data Lake.
Data Federation: The End of Rigid ETL Pipelines
Historically, we Basis Administrators built massive ETL pipelines (Extract, Transform, Load) to physically copy data from external systems (Oracle, MSSQL, Hadoop) via SLT or Data Services into HANA. This led to massive data redundancies and network loads.
SAP HANA Cloud establishes the concept of Data Federation as the new standard, orchestrated via Smart Data Access (SDA) and Smart Data Integration (SDI).
Instead of copying data, HANA Cloud acts as a unified gateway. It connects directly to external hyperscaler services like Amazon S3, Google BigQuery, or Azure Data Lake via native adapters. The tables of the third-party systems are represented as Virtual Tables in HANA. When a Fiori dashboard issues a query, HANA Cloud translates the query, pushes it to the source system, lets it perform the calculations, and only aggregates the final result set back into the main memory.
Security, Administration, and the BTP Ecosystem
With the shift to the cloud, classic Basis tasks like OS patching or hardware sizing disappear, but the security architecture becomes more complex. SAP HANA Cloud is exclusively available via the SAP Business Technology Platform (BTP).
Administration shifts entirely from the local HANA Studio to the web-based SAP HANA Cockpit and the SAP HANA Database Explorer. The authorization concept relies on strong encryption (Data-at-Rest and Data-in-Motion) as well as integration into the BTP's identity management.
Furthermore, HANA Cloud is the engine for the similarly realigned SAP Data Warehouse Cloud (DWC). Without the virtualization and Data Lake capabilities of HANA Cloud, the semantic layer of DWC would not be feasible.
Conclusion for Architects
The launch of SAP HANA Cloud in 2020 is far more than just a hosting offering. It is an architectural realignment. In-memory technology is freed from its physical hardware shackles.
For us Enterprise Architects, this means: The stubborn "everything-in-RAM" sizing is over. The art of modern data architecture now consists of precisely defining data lifecycles (Hot/Warm/Cold), efficiently using the new SAP IQ-based Data Lake, and virtually connecting external data silos via federation without duplicating them. Those who master these cloud-native storage concepts will build the most scalable and cost-efficient SAP landscapes of the coming decade.