Willkommen zurück im Architektur-Blog. In diesem Frühjahr feiern wir ein massives Jubiläum in der Enterprise-IT: 10 Jahre SAP HANA. Was 2010 als rasend schnelle, aber extrem starre On-Premise-Appliance begann, hat nun seinen vorläufigen evolutionären Höhepunkt erreicht. Mit dem offiziellen Launch der SAP HANA Cloud vollzieht SAP den radikalen Schnitt von der Appliance hin zu einer echten, nativen Database-as-a-Service (DBaaS).
Dieser Artikel ist kein Marketing-Recap, sondern ein Deep-Dive in die veränderte Systemarchitektur, die Speicher-Hierarchien und die neuen Paradigmen, die wir als Basis- und Datenbank-Administratoren ab sofort beherrschen müssen.
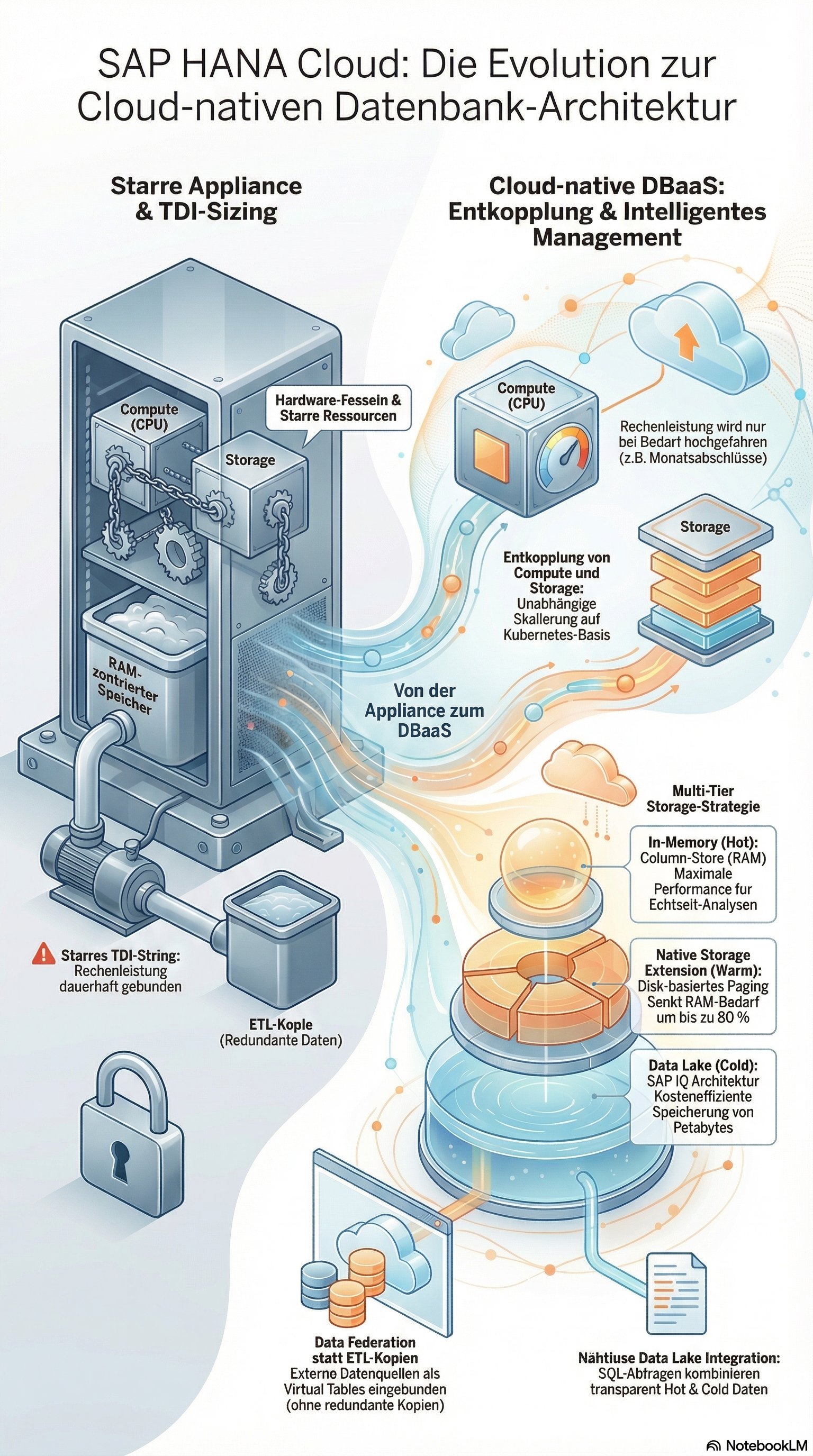
Der fundamentale Shift: Entkopplung von Compute und Storage
Der größte architektonische Flaschenhals klassischer HANA On-Premise-Installationen war die enge Kopplung von CPU und RAM. Ein Scale-Up bedeutete oft teure Hardware-Upgrades, bei denen Speicher und Rechenleistung im festen Verhältnis (z. B. im TDI-Sizing) skaliert werden mussten, selbst wenn nur mehr Speicherplatz benötigt wurde.
SAP HANA Cloud bricht dieses Konstrukt auf Basis moderner Container-Orchestrierung (unter der Haube Kubernetes) vollständig auf. Compute-Nodes und Storage-Ressourcen lassen sich nun völlig unabhängig voneinander skalieren. Braucht ein Monatsabschluss massiv CPU-Power, skaliert das Compute-Tier hoch. Wird danach nur Archiv-Speicher benötigt, skaliert das Storage-Tier, während die CPUs heruntergefahren werden. Dies ist der Schlüssel zu einer massiven TCO-Reduzierung (Total Cost of Ownership).
Multi-Tier Storage: Von In-Memory bis zum Data Lake
Die Architektur der SAP HANA Cloud zwingt uns, Daten nicht mehr stur im RAM zu halten, sondern eine intelligente Multi-Tier-Storage-Strategie zu designen:
-
In-Memory (Hot Data): Der klassische HANA Column-Store. Teuer, aber mit Latenzen im Nanosekundenbereich für geschäftskritische Echtzeitanalysen und Transaktionen.
-
Native Storage Extension (NSE) (Warm Data): Eine integrierte Disk-basierte Erweiterung. Daten, die seltener genutzt werden (z. B. historische FI-Belege des Vorjahres), werden hierher verschoben. Durch Paging-Mechanismen wird der RAM-Bedarf um bis zu 80 % gesenkt, bei nur moderatem Performance-Verlust.
-
SAP HANA Cloud, Data Lake (Cold Data): Hier liegt der wahre architektonische Neuzugang. Der Data Lake Relational Engine basiert technologisch auf der massiv-parallelen SAP IQ-Datenbankarchitektur. Er ist darauf ausgelegt, Petabytes an unstrukturierten und strukturierten Daten extrem kosteneffizient zu speichern. Der Clou: Der Data Lake ist nahtlos in die HANA-Abfrage-Engine integriert. Ein SQL-Query kann Daten aus dem In-Memory-Speicher transparent mit Daten aus dem Data Lake joinen.
Data Federation: Das Ende der starren ETL-Pipelines
Historisch haben wir Basis-Administratoren gewaltige ETL-Pipelines (Extract, Transform, Load) gebaut, um Daten aus externen Systemen (Oracle, MSSQL, Hadoop) via SLT oder Data Services physisch in die HANA zu kopieren. Das führte zu massiven Datenredundanzen und Netzwerklasten.
SAP HANA Cloud etabliert das Konzept der Data Federation als neuen Standard, orchestriert über Smart Data Access (SDA) und Smart Data Integration (SDI).
Anstatt Daten zu kopieren, fungiert HANA Cloud als einheitliches Gateway. Sie verbindet sich über native Adapter direkt mit externen Hyperscaler-Diensten wie Amazon S3, Google BigQuery oder Azure Data Lake. Die Tabellen der Drittsysteme werden als Virtual Tables in der HANA repräsentiert. Wenn ein Fiori-Dashboard eine Abfrage absetzt, übersetzt die HANA Cloud den Query, pusht ihn an das Quellsystem, lässt dieses die Berechnungen durchführen und aggregiert nur das finale Result-Set zurück in den Hauptspeicher.
Security, Administration und das BTP-Ökosystem
Mit dem Shift in die Cloud entfallen klassische Basis-Aufgaben wie OS-Patching oder Hardware-Sizing, doch die Security-Architektur wird komplexer. SAP HANA Cloud ist exklusiv über die SAP Business Technology Platform (BTP) verfügbar.
Die Administration verschiebt sich vom lokalen HANA Studio vollständig in das webbasierte SAP HANA Cockpit und den SAP HANA Database Explorer. Das Berechtigungskonzept stützt sich auf starke Verschlüsselung (Data-at-Rest und Data-in-Motion) sowie auf die Integration in das Identitätsmanagement der BTP.
Zudem ist HANA Cloud der Motor für das ebenfalls neu ausgerichtete SAP Data Warehouse Cloud (DWC). Ohne die Virtualisierungs- und Data-Lake-Fähigkeiten der HANA Cloud wäre der semantische Layer des DWC nicht realisierbar.
Fazit für Architekten
Der Launch der SAP HANA Cloud im Jahr 2020 ist weit mehr als nur ein Hosting-Angebot. Es ist eine architektonische Neuausrichtung. Die In-Memory-Technologie wird von ihren physischen Hardware-Fesseln befreit.
Für uns Enterprise-Architekten bedeutet das: Das sture "Alles-in-den-RAM"-Sizing ist vorbei. Die Kunst der modernen Datenarchitektur besteht ab sofort darin, Datenlebenszyklen präzise zu definieren (Hot/Warm/Cold), den neuen SAP IQ-basierten Data Lake effizient zu nutzen und externe Datensilos mittels Federation virtuell anzubinden, ohne sie zu duplizieren. Wer diese Cloud-nativen Speicherkonzepte meistert, baut die skalierbarsten und kosteneffizientesten SAP-Landschaften des kommenden Jahrzehnts.