Welcome back to the architectural drawing board! In spring 2024, SAP delivered arguably the most critical database release of the AI era: the native SAP HANA Vector Engine (available in SAP HANA Cloud). Why is this an architectural earthquake? Because it solves the fundamental problem of Large Language Models (LLMs) in the enterprise context: hallucinations and missing company knowledge.
As a Senior SAP Technology Consultant, today I am taking a deep, unvarnished look at the technology of vector embeddings, the new SQL data type in HANA, and the architectural pattern of Retrieval-Augmented Generation (RAG) on the SAP BTP.
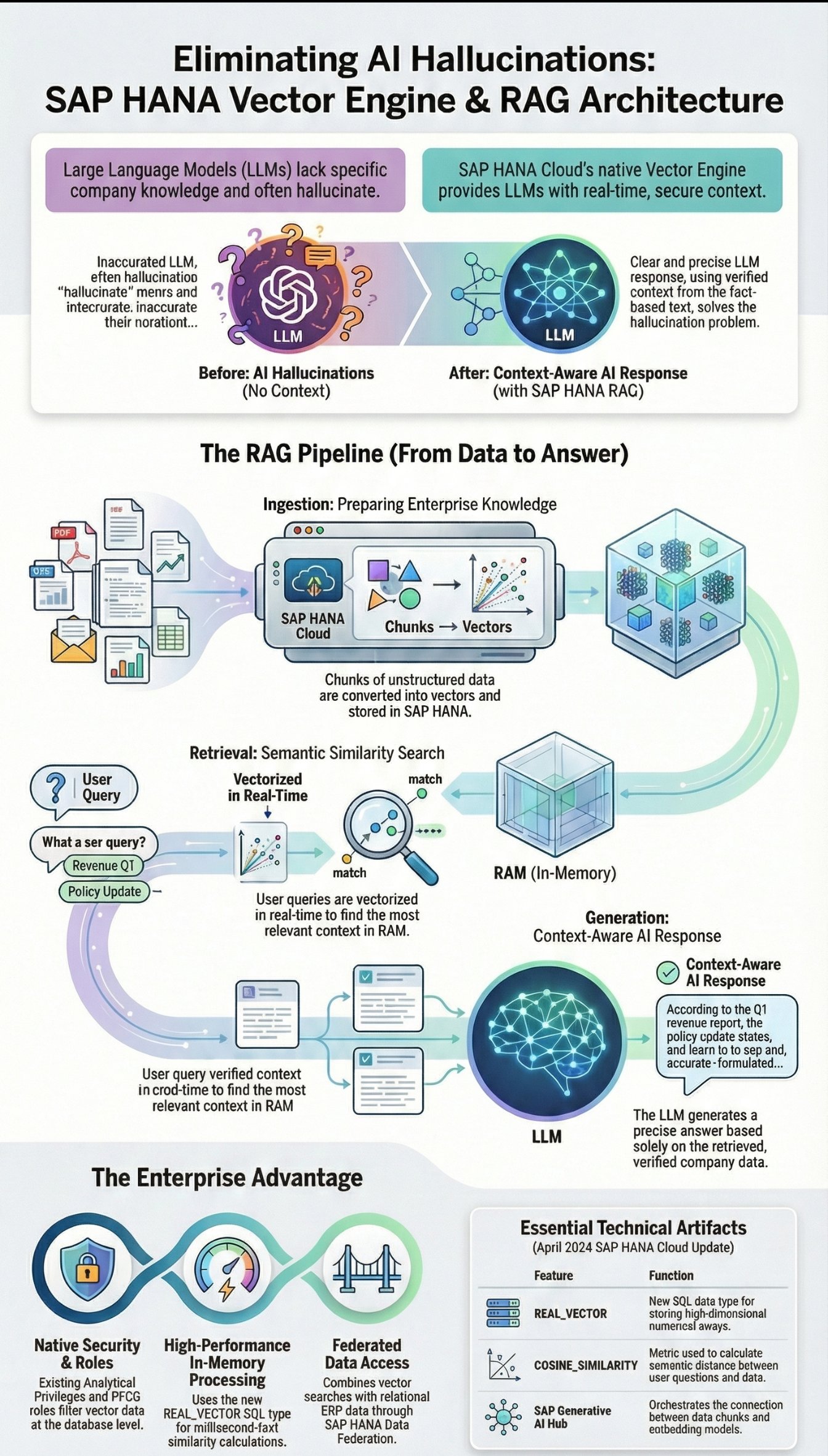
The Problem: The LLM Does Not Know Your Contracts
An LLM (like GPT-4) is a brilliant linguistic genius, but it has no idea about your specific supplier contracts, internal service tickets, or HR policies. Do we retrain the model with this data (fine-tuning)? No – it's too expensive, too rigid, and an absolute nightmare for authorization concepts (PFCG roles).
The solution is called RAG (Retrieval-Augmented Generation). Instead of training the model, we dynamically provide it with the relevant context in the prompt. To ensure the system finds the right paragraph from millions of PDF documents and texts in milliseconds, we need semantic search. And this is exactly where the vector database comes into play.
Deep Dive: The SAP HANA Vector Engine
Previously, architects had to connect external vector databases (like Pinecone, Milvus, or Weaviate) for RAG setups. This meant data replication, network latency, and breaking SAP security boundaries.
With the update in April 2024, SAP natively integrates this capability into the in-memory Column Store of the HANA Cloud.
Texts are transformed into high-dimensional numerical arrays (vectors) by an embedding model (e.g., text-embedding-ada-002 via SAP AI Core). A text paragraph thus becomes an array of thousands of floating-point numbers.
Technically, HANA Cloud introduces new SQL artifacts for this:
-
The
REAL_VECTORData Type: Tables can now accommodate vector columns.sql CREATE TABLE DOCUMENT_STORE ( DOC_ID NVARCHAR(32) PRIMARY KEY, CONTENT NCLOB, VECTOR_EMBEDDING REAL_VECTOR(1536) ); -
Similarity Search Functions: To find out which text section is semantically most similar to a user's question, HANA calculates the distance between the vectors in RAM. For this, it uses metrics like
COSINE_SIMILARITYorL2DISTANCE.
The Architecture of a RAG Pipeline on SAP BTP
How do we orchestrate this in a real enterprise landscape? The setup runs via the SAP Business Technology Platform (BTP):
Phase 1: Ingestion (Data Preparation)
-
Unstructured data (e.g., PDF maintenance manuals) is broken down into small text sections (chunks).
-
The chunks are sent to an embedding model via the SAP Generative AI Hub.
-
The model returns the vector.
-
Chunk (text) + Vector (numerical array) are stored in the SAP HANA Cloud.
Phase 2: Retrieval & Generation (At Runtime)
-
The maintenance technician types into the Fiori app: "How do I replace the sealing ring on pump P-400?"
-
The application (e.g., a CAP Node.js app) converts this question into a vector in real-time.
-
The app fires an SQL query at the HANA Cloud:
sql SELECT TOP 3 CONTENT FROM DOCUMENT_STORE ORDER BY COSINE_SIMILARITY(VECTOR_EMBEDDING, TO_REAL_VECTOR('[0.012, -0.045, ...]')) DESC; -
Within milliseconds, HANA finds the 3 most relevant manual paragraphs.
-
The app builds a meta-prompt: "Answer the user's question based on the following context: [The 3 paragraphs]".
-
This prompt goes to the LLM (e.g., GPT-4), which generates a precise, factually correct, and cited response.
Security and Authorizations: The Enterprise Advantage
The most massive advantage of this architecture over external startups is security. Because the vectors physically reside in the SAP HANA Cloud, classic Analytical Privileges apply.
If a clerk initiates a RAG query across HR documents, HANA Cloud automatically filters the vector search at the database level (via SQL WHERE clauses) so that they can only search documents for which they have explicit authorization.
Federated RAG: Moreover, these vector searches can be seamlessly linked with relational ERP data via the HANA Data Federation concept (SDA) (e.g., "Show me the manual for the material ordered in sales order 4711").
Conclusion for Architects
The in-memory database market has evolved from purely relational storage to a multi-model approach. SAP HANA Cloud now processes relational data, spatial data, graphs, and vectors in a single engine.
For us IT architects, 2024 marks the entry into the true AI implementation phase. Knowledge of COSINE_SIMILARITY, document chunking, and orchestrating the SAP Generative AI Hub alongside CAP (Cloud Application Programming) becomes a core competency. Anyone who can securely build RAG architectures on the SAP BTP transforms LLMs from risky toys into highly precise, trustworthy enterprise tools.