Willkommen zurück am Architektur-Reißbrett! Im Frühjahr 2024 hat SAP das wohl kritischste Datenbank-Release der KI-Ära ausgeliefert: Die native SAP HANA Vector Engine (verfügbar in SAP HANA Cloud). Warum ist das ein architektonisches Erdbeben? Weil es das fundamentale Problem von Large Language Models (LLMs) im Enterprise-Kontext löst: Halluzinationen und fehlendes Firmenwissen.
Als Senior SAP Technology Consultant werfe ich heute einen tiefen, ungeschönten Blick auf die Technologie der Vektor-Embeddings, den neuen SQL-Datentyp in HANA und das Architektur-Muster der Retrieval-Augmented Generation (RAG) auf der SAP BTP.
Das Problem: Das LLM kennt deine Verträge nicht
Ein LLM (wie GPT-4) ist ein brillantes Sprachgenie, aber es hat keine Ahnung von euren spezifischen Lieferantenverträgen, internen Service-Tickets oder HR-Richtlinien. Trainiert man das Modell mit diesen Daten nach (Fine-Tuning)? Nein – zu teuer, zu starr und ein absoluter Albtraum für Berechtigungskonzepte (PFCG-Rollen).
Die Lösung heißt RAG (Retrieval-Augmented Generation). Anstatt das Modell zu trainieren, geben wir ihm den relevanten Kontext dynamisch im Prompt mit. Damit das System in Millisekunden aus Millionen von PDF-Dokumenten und Texten den richtigen Absatz findet, brauchen wir eine semantische Suche. Und exakt hier kommt die Vektordatenbank ins Spiel.
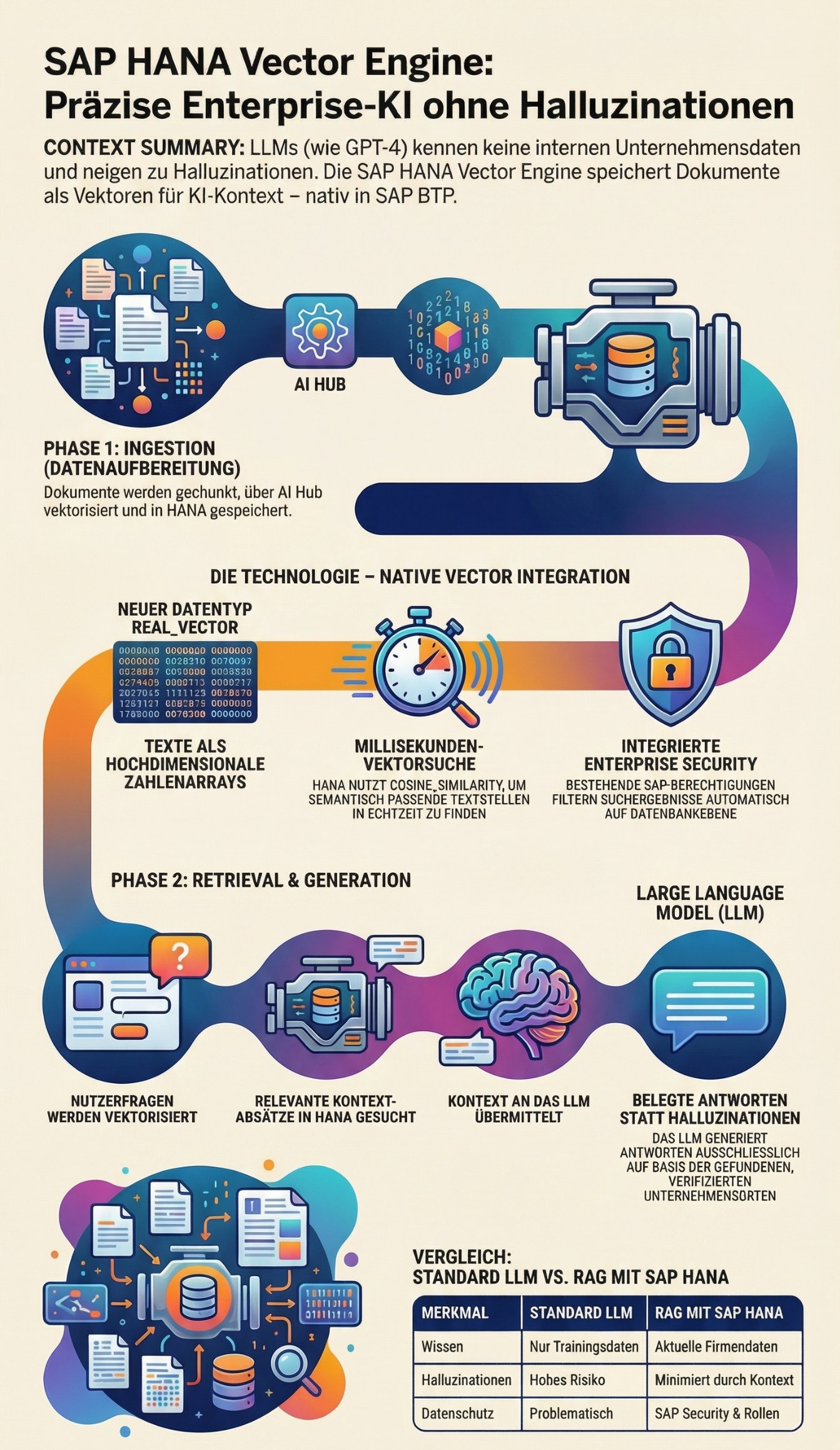
Deep-Dive: Die SAP HANA Vector Engine
Bisher mussten Architekten für RAG-Setups externe Vektordatenbanken (wie Pinecone, Milvus oder Weaviate) anbinden. Das bedeutete: Datenreplikation, Netzwerklatenz und das Brechen der SAP-Sicherheitsgrenzen.
Mit dem Update im April 2024 integriert SAP diese Funktion nativ in den In-Memory Column Store der HANA Cloud.
Texte werden durch ein Embedding-Modell (z.B. text-embedding-ada-002 via SAP AI Core) in hochdimensionale Zahlenarrays (Vektoren) verwandelt. Ein Textabsatz wird so zu einem Array aus tausenden Fließkommazahlen.
Technisch bringt HANA Cloud dafür neue SQL-Artefakte mit:
-
Der Datentyp
REAL_VECTOR: Tabellen können nun Vektorspalten aufnehmen.sql CREATE TABLE DOCUMENT_STORE ( DOC_ID NVARCHAR(32) PRIMARY KEY, CONTENT NCLOB, VECTOR_EMBEDDING REAL_VECTOR(1536) ); -
Similarity Search Funktionen: Um herauszufinden, welcher Textabschnitt einer User-Frage semantisch am ähnlichsten ist, berechnet die HANA die Distanz zwischen den Vektoren im RAM. Dafür nutzt sie Metriken wie
COSINE_SIMILARITYoderL2DISTANCE.
Die Architektur einer RAG-Pipeline auf der SAP BTP
Wie orchestrieren wir das nun in einer echten Enterprise-Landschaft? Das Setup läuft über die SAP Business Technology Platform (BTP):
Phase 1: Ingestion (Datenaufbereitung)
-
Unstrukturierte Daten (z. B. PDF-Wartungshandbücher) werden in kleine Textabschnitte (Chunks).
-
Die Chunks werden über den SAP Generative AI Hub an ein Embedding-Modell gesendet.
-
Das Modell liefert den Vektor zurück.
-
Chunk (Text) + Vektor (Zahlenarray) werden in der SAP HANA Cloud gespeichert.
Phase 2: Retrieval & Generation (Zur Laufzeit)
-
Der Instandhalter tippt in die Fiori-App: "Wie tausche ich den Dichtungsring an der Pumpe P-400?"
-
Die Applikation (z. B. eine CAP Node.js App) wandelt diese Frage in Echtzeit in einen Vektor um.
-
Die App feuert einen SQL-Query an die HANA Cloud:
sql SELECT TOP 3 CONTENT FROM DOCUMENT_STORE ORDER BY COSINE_SIMILARITY(VECTOR_EMBEDDING, TO_REAL_VECTOR('[0.012, -0.045, ...]')) DESC; -
Die HANA findet in Millisekunden die 3 relevantesten Handbuch-Absätze.
-
Die App baut einen Meta-Prompt: "Beantworte die Frage des Users basierend auf folgendem Kontext: [Die 3 Absätze]".
-
Dieser Prompt geht an das LLM (z.B. GPT-4), welches eine präzise, fachlich korrekte und belegte Antwort generiert.
Security und Berechtigungen: Der Enterprise-Vorteil
Der massivste Vorteil dieser Architektur gegenüber externen Startups ist die Security. Da die Vektoren physisch in der SAP HANA Cloud liegen, greifen die klassischen Analytical Privileges.
Wenn ein Sachbearbeiter eine RAG-Abfrage über HR-Dokumente startet, filtert die HANA Cloud auf Datenbankebene (via SQL WHERE-Klauseln) die Vektor-Suche automatisch so ein, dass er nur die Dokumente durchsuchen kann, für die er eine explizite Berechtigung besitzt.
Federated RAG: Zudem lassen sich diese Vektor-Suchen über das HANA Data Federation-Konzept (SDA) nahtlos mit relationalen ERP-Daten verknüpfen (z.B. "Zeige mir das Handbuch für das Material, das in Kundenauftrag 4711 bestellt wurde").
Fazit für Architekten
Der In-Memory-Datenbankmarkt hat sich von der rein relationalen Speicherung zu einem Multi-Model-Ansatz entwickelt. SAP HANA Cloud verarbeitet nun relationale Daten, Geodaten (Spatial), Graphen und Vektoren in einer einzigen Engine.
Für uns IT-Architekten bedeutet das Jahr 2024 den Eintritt in die echte KI-Implementierungsphase. Das Wissen um COSINE_SIMILARITY, das Chunking von Dokumenten und die Orchestrierung des SAP Generative AI Hubs zusammen mit CAP (Cloud Application Programming) wird zur Kernkompetenz. Wer RAG-Architekturen sicher auf der SAP BTP aufbauen kann, transformiert LLMs von riskanten Spielzeugen zu hochpräzisen, vertrauenswürdigen Unternehmenswerkzeugen.